【总结了14种数据异常值检验的方法是】本文约7100字,建议阅读10+分钟
文章插图
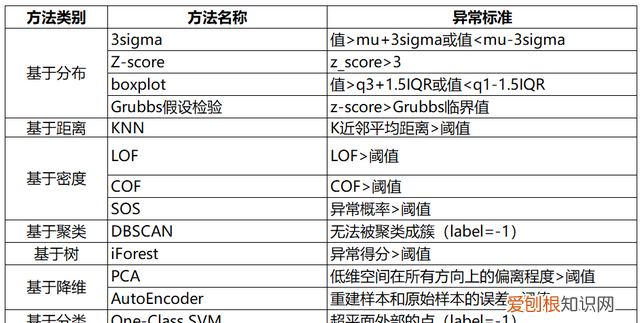
一、基于分布的方法
1. 3sigma
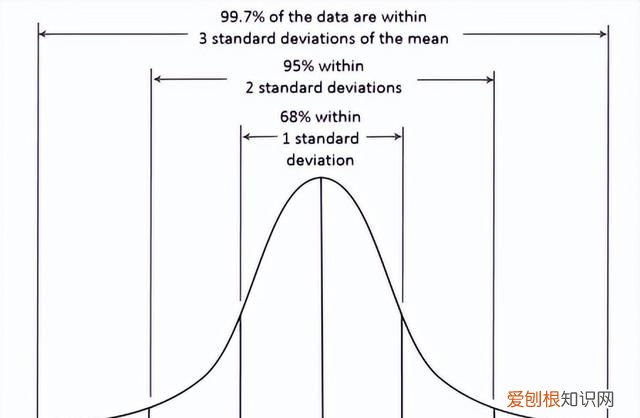
基于正态分布,3sigma准则认为超过3sigma的数据为异常点 。
文章插图
图1: 3sigma
def three_sigma(s): mu, std = np.mean(s), np.std(s) lower, upper = mu-3*std, mu+3*std return lower, upper2. Z-score
Z-score为标准分数,测量数据点和平均值的距离,若A与平均值相差2个标准差,Z-score为2 。当把Z-score=3作为阈值去剔除异常点时,便相当 3sigma 。
def z_score(s): z_score = (s - np.mean(s)) / np.std(s) return z_scorebr3. boxplot
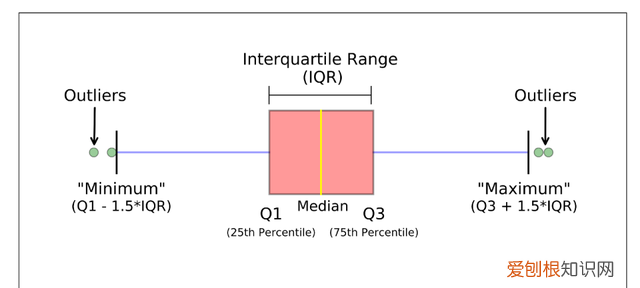
箱线图时基于四分位距(IQR)找异常点的 。
文章插图
图2: boxplot
def boxplot(s): q1, q3 = s.quantile(.25), s.quantile(.75) iqr = q3 - q1 lower, upper = q1 - 1.5*iqr, q3 + 1.5*iqr return lower, upper4. Grubbs假设检验
[1] 时序预测竞赛之异常检测算法综述 - 鱼遇雨欲语与余,知乎:***/p/336944097
[2] 剔除异常值栅格计算器_数据分析师所需的统计学:异常检测 - weixin_39974030,CSDN:***/weixin_39974030/article/details/112569610
Grubbs’Test为一种假设检验的方法,常被用来检验服从正态分布的单变量数据集(univariate data set)Y中的单个异常值 。若有异常值,则其必为数据集中的最大值或最小值 。原假设与备择假设如下:
● H0: 数据集中没有异常值
● H1: 数据集中有一个异常值
使用Grubbs测试需要总体是正态分布的 。算法流程:
1. 样本从小到大排序;
2. 求样本的mean和dev;
3. 计算min/max与mean的差距,更大的那个为可疑值;
4. 求可疑值的z-score (standard score),如果大于Grubbs临界值,那么就是outlier 。
Grubbs临界值可以查表得到,它由两个值决定:检出水平α(越严格越小),样本数量n,排除outlier,对剩余序列循环做 1-4 步骤 [1] 。详细计算样例可以参考 。
from outliers import smirnov_grubbs as grubbsprint(grubbs.test([8, 9, 10, 1, 9], alpha=0.05))print(grubbs.min_test_outliers([8, 9, 10, 1, 9], alpha=0.05))print(grubbs.max_test_outliers([8, 9, 10, 1, 9], alpha=0.05))print(grubbs.max_test_indices([8, 9, 10, 50, 9], alpha=0.05))局限:
1. 只能检测单维度数据;
2. 无法精确的输出正常区间;
3. 它的判断机制是“逐一剔除”,所以每个异常值都要单独计算整个步骤,数据量大吃不消;
4. 需假定数据服从正态分布或近正态分布 。
二、基于距离的方法
1. KNN
[3] 异常检测算法之(KNN)-K Nearest Neighbors - 小伍哥聊风控,知乎:***/p/501691799
依次计算每个样本点与它最近的K个样本的平均距离,再利用计算的距离与阈值进行比较,如果大于阈值,则认为是异常点 。优点是不需要假设数据的分布,缺点是仅可以找出全局异常点,无法找到局部异常点 。
from pyod.models.knn import KNN# 初始化检测器clfclf = KNN( method='mean', n_neighbors=3, )clf.fit(X_train)# 返回训练数据上的分类标签 (0: 正常值, 1: 异常值)y_train_pred = clf.labels_# 返回训练数据上的异常值 (分值越大越异常)y_train_scores = clf.decision_scores_
推荐阅读
-

-
-
-
-

-
-
-
-
-
- 考研性价比高的专业,适合考研的专业有哪些
- 要如何看电脑型号,怎么才能知道自己电脑的型号?
- vcf文件要怎么转换成excel
- 韩国人为什么喜欢上吊 为什么自杀的人喜欢上吊
- 安卓手机怎么截图,安卓手机如何截屏
- 为什么自杀的人不顾亲人的感受
- 公主为什么自称哀家 为什么自称哀家
- 坎普为什么被称为雨人 为什么周伟被称为中国雨人
- 周鹏为什么能当队长 为什么周鹏是队长