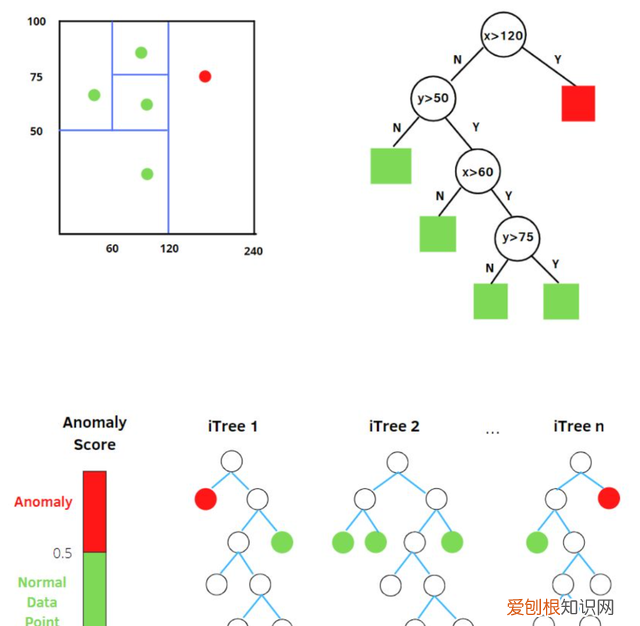
我们用一个随机超平面对一个数据空间进行切割,切一次可以生成两个子空间 。接下来,我们再继续随机选取超平面,来切割第一步得到的两个子空间,以此循环下去,直到每子空间里面只包含一个数据点为止 。我们可以发现,那些密度很高的簇要被切很多次才会停止切割,即每个点都单独存在于一个子空间内,但那些分布稀疏的点,大都很早就停到一个子空间内了 。所以,整个孤立森林的算法思想:异常样本更容易快速落入叶子结点或者说,异常样本在决策树上,距离根节点更近 。
随机选择m个特征,通过在所选特征的最大值和最小值之间随机选择一个值来分割数据点 。观察值的划分递归地重复,直到所有的观察值被孤立 。
文章插图
图10:孤立森林
获得 t 个孤立树后,单棵树的训练就结束了 。接下来就可以用生成的孤立树来评估测试数据了,即计算异常分数 s 。对于每个样本 x,需要对其综合计算每棵树的结果,通过下面的公式计算异常得分:
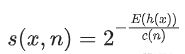
文章插图
● h(x):为样本在iTree上的PathLength;
● E(h(x)):为样本在t棵iTree的PathLength的均值;
● c(n):为n个样本构建一个二叉搜索树BST中的未成功搜索平均路径长度(均值h(x)对外部节点终端的估计等同于BST中的未成功搜索) 。
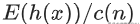
文章插图
是对样本x的路径长度h(x)进行标准化处理 。H(n-1)是调和数,可使用ln(n-1)+0.5772156649(欧拉常数)估算 。
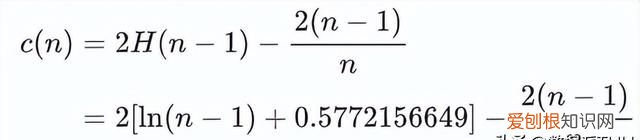
文章插图
指数部分值域为(?∞,0),因此s值域为(0,1) 。当PathLength越小,s越接近1,此时样本为异常值的概率越大 。
# Ref:***/p/484495545from sklearn.datasets import load_iris from sklearn.ensemble import IsolatiOnForestdata= http://www.baifabohui.com/smjk/load_iris(as_frame=True) X,y = data.data,data.target df = data.frame # 模型训练iforest = IsolationForest(n_estimators=100, max_samples='auto', cOntamination=0.05, max_features=4, bootstrap=False, n_jobs=-1, random_state=1)# fit_predict 函数 训练和预测一起 可以得到模型是否异常的判断,-1为异常,1为正常df['label'] = iforest.fit_predict(X) # 预测 decision_function 可以得出 异常评分df['scores'] = iforest.decision_function(X)六、基于降维的方法
1. Principal Component Analysis (PCA)
[11] 机器学习-异常检测算法(三):Principal Component Analysis - 刘腾飞,知乎:***/p/29091645
[12] Anomaly Detection异常检测--PCA算法的实现 - CC思SS,知乎:***/p/48110105
PCA在异常检测方面的做法,大体有两种思路:
(1) 将数据映射到低维特征空间,然后在特征空间不同维度上查看每个数据点跟其它数据的偏差;
(2) 将数据映射到低维特征空间,然后由低维特征空间重新映射回原空间,尝试用低维特征重构原始数据,看重构误差的大小 。
PCA在做特征值分解,会得到:
● 特征向量:反应了原始数据方差变化程度的不同方向;
● 特征值:数据在对应方向上的方差大小 。
所以,最大特征值对应的特征向量为数据方差最大的方向,最小特征值对应的特征向量为数据方差最小的方向 。原始数据在不同方向上的方差变化反应了其内在特点 。如果单个数据样本跟整体数据样本表现出的特点不太一致,比如在某些方向上跟其它数据样本偏离较大,可能就表示该数据样本是一个异常点 。
推荐阅读


- 考研性价比高的专业,适合考研的专业有哪些
- 要如何看电脑型号,怎么才能知道自己电脑的型号?
- vcf文件要怎么转换成excel
- 韩国人为什么喜欢上吊 为什么自杀的人喜欢上吊
- 安卓手机怎么截图,安卓手机如何截屏
- 为什么自杀的人不顾亲人的感受
- 公主为什么自称哀家 为什么自称哀家
- 坎普为什么被称为雨人 为什么周伟被称为中国雨人
- 周鹏为什么能当队长 为什么周鹏是队长