在前面提到第一种做法中,样本$x_i$的异常分数为该样本在所有方向上的偏离程度:
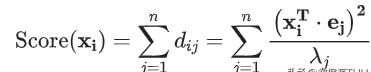
文章插图
其中,
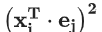
文章插图
为样本在重构空间里离特征向量的距离 。若存在样本点偏离各主成分越远,
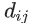
文章插图
会越大,意味偏移程度大,异常分数高 。
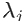
文章插图
是特征值,用于归一化,使不同方向上的偏离程度具有可比性 。
在计算异常分数时,关于特征向量(即度量异常用的标杆)选择又有两种方式:
● 考虑在前k个特征向量方向上的偏差:前k个特征向量往往直接对应原始数据里的某几个特征,在前几个特征向量方向上偏差比较大的数据样本,往往就是在原始数据中那几个特征上的极值点 。
● 考虑后r个特征向量方向上的偏差:后r个特征向量通常表示某几个原始特征的线性组合,线性组合之后的方差比较小反应了这几个特征之间的某种关系 。在后几个特征方向上偏差比较大的数据样本,表示它在原始数据里对应的那几个特征上出现了与预计不太一致的情况 。
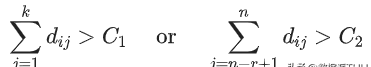
文章插图
得分大于阈值C则判断为异常 。
第二种做法,PCA提取了数据的主要特征,如果一个数据样本不容易被重构出来,表示这个数据样本的特征跟整体数据样本的特征不一致,那么它显然就是一个异常的样本:
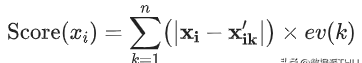
文章插图
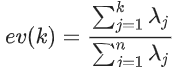
文章插图
其中,
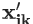
文章插图
是基于k维特征向量重构的样本 。
基于低维特征进行数据样本的重构时,舍弃了较小的特征值对应的特征向量方向上的信息 。换一句话说,重构误差其实主要来自较小的特征值对应的特征向量方向上的信息 。基于这个直观的理解,PCA在异常检测上的两种不同思路都会特别关注较小的特征值对应的特征向量 。所以,我们说PCA在做异常检测时候的两种思路本质上是相似的,当然第一种方法还可以关注较大特征值对应的特征向量 。
# Ref: [***/p/48110105](***/p/48110105)from sklearn.decomposition import PCApca = PCA()pca.fit(centered_training_data)transformed_data = http://www.baifabohui.com/smjk/pca.transform(training_data)y = transformed_data# 计算异常分数lambdas = pca.singular_values_M = ((y*y)/lambdas)# 前k个特征向量和后r个特征向量q = 5print "Explained variance by first q terms: ", sum(pca.explained_variance_ratio_[:q])q_values = list(pca.singular_values_ < .2)r = q_values.index(True)# 对每个样本点进行距离求和的计算major_compOnents= M[:,range(q)]minor_compOnents= M[:,range(r, len(features))]major_compOnents= np.sum(major_components, axis=1)minor_compOnents= np.sum(minor_components, axis=1)# 人为设定c1、c2阈值compOnents= pd.DataFrame({'major_components': major_components, 'minor_components': minor_components})c1 = components.quantile(0.99)['major_components']c2 = components.quantile(0.99)['minor_components']# 制作分类器def classifier(major_components, minor_components): major = major_components > c1 minor = minor_components > c2 return np.logical_or(major,minor)results = classifier(major_compOnents=major_components, minor_compOnents=minor_components)
推荐阅读
-

-
-
-
-

-
-
-
-
-
- 考研性价比高的专业,适合考研的专业有哪些
- 要如何看电脑型号,怎么才能知道自己电脑的型号?
- vcf文件要怎么转换成excel
- 韩国人为什么喜欢上吊 为什么自杀的人喜欢上吊
- 安卓手机怎么截图,安卓手机如何截屏
- 为什么自杀的人不顾亲人的感受
- 公主为什么自称哀家 为什么自称哀家
- 坎普为什么被称为雨人 为什么周伟被称为中国雨人
- 周鹏为什么能当队长 为什么周鹏是队长