3. Stochastic Outlier Selection (SOS)
[7] 异常检测之SOS算法 - 呼广跃,知乎:***/p/34438518
将特征矩阵(feature martrix)或者相异度矩阵(dissimilarity matrix)输入给SOS算法,会返回一个异常概率值向量(每个点对应一个) 。SOS的思想是:当一个点和其它所有点的关联度(affinity)都很小的时候,它就是一个异常点 。
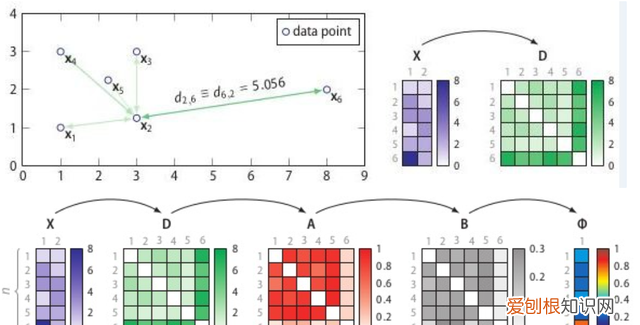
文章插图
图6:SOS计算流程
SOS的流程:
1. 计算相异度矩阵D;
2. 计算关联度矩阵A;
3. 计算关联概率矩阵B;
4. 算出异常概率向量 。
相异度矩阵D是各样本两两之间的度量距离,比如欧式距离或汉明距离等 。关联度矩阵反映的是度量距离方差,如图7,点 的密度最大,方差最小; 的密度最小,方差最大 。而关联概率矩阵B(binding probability matrix)就是把关联矩阵(affinity matrix)按行归一化得到的,如图8所示 。
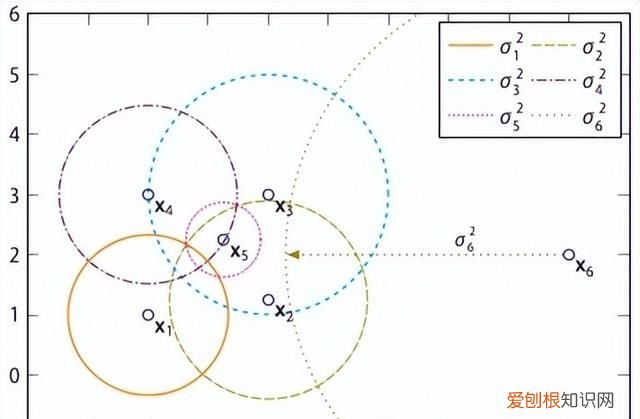
文章插图
图7:关联度矩阵中密度可视化
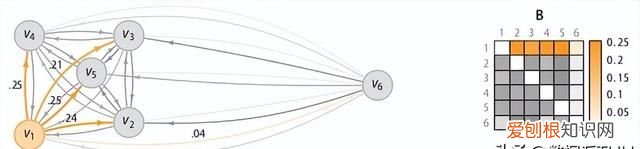
文章插图
图8:关联概率矩阵
得到了binding probability matrix,每个点的异常概率值就用如下的公式计算,当一个点和其它所有点的关联度(affinity)都很小的时候,它就是一个异常点 。
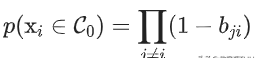
文章插图
# Ref: ***/jeroenjanssens/scikit-sosimport pandas as pdfrom sksos import SOSiris = pd.read_csv("http://bit.ly/iris-csv")X = iris.drop("Name", axis=1).valuesdetector = SOS()iris["score"] = detector.predict(X)iris.sort_values("score", ascending=False).head(10)四、基于聚类的方法
1. DBSCAN
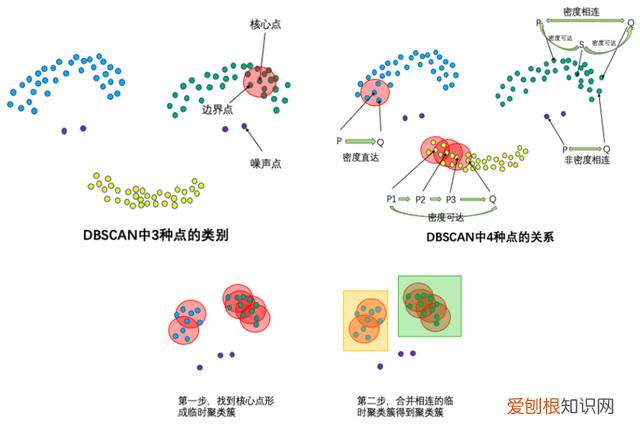
DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)的输入和输出如下,对于无法形成聚类簇的孤立点,即为异常点(噪声点) 。
● 输入:数据集,邻域半径Eps,邻域中数据对象数目阈值MinPts;
● 输出:密度联通簇 。
文章插图
图9:DBSCAN
处理流程如下:
1. 从数据集中任意选取一个数据对象点p;
2. 如果对于参数Eps和MinPts,所选取的数据对象点p为核心点,则找出所有从p密度可达的数据对象点,形成一个簇;
3. 如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
4. 重复以上2、3步,直到所有点被处理 。
# Ref: ***/p/515268801from sklearn.cluster import DBSCANimport numpy as npX = np.array([[1, 2], [2, 2], [2, 3], [8, 7], [8, 8], [25, 80]])clustering = DBSCAN(eps=3, min_samples=2).fit(X)clustering.labels_array([ 0, 0, 0, 1, 1, -1])# 0,,0,,0:表示前三个样本被分为了一个群# 1, 1:中间两个被分为一个群# -1:最后一个为异常点,不属于任何一个群五、基于树的方法
1. Isolation Forest (iForest)
[8] 异常检测算法 -- 孤立森林(Isolation Forest)剖析 - 风控大鱼,知乎:***/p/74508141
[9] 孤立森林(isolation Forest)-一个通过瞎几把乱分进行异常检测的算法 - 小伍哥聊风控,知乎:***/p/484495545
[10] 孤立森林阅读 - Mark_Aussie,博文:***/MarkAustralia/article/details/120181899
孤立森林中的 “孤立” (isolation) 指的是 “把异常点从所有样本中孤立出来”,论文中的原文是 “separating an instance from the rest of the instances” 。
推荐阅读


- 考研性价比高的专业,适合考研的专业有哪些
- 要如何看电脑型号,怎么才能知道自己电脑的型号?
- vcf文件要怎么转换成excel
- 韩国人为什么喜欢上吊 为什么自杀的人喜欢上吊
- 安卓手机怎么截图,安卓手机如何截屏
- 为什么自杀的人不顾亲人的感受
- 公主为什么自称哀家 为什么自称哀家
- 坎普为什么被称为雨人 为什么周伟被称为中国雨人
- 周鹏为什么能当队长 为什么周鹏是队长