三、基于密度的方法
1. Local Outlier Factor (LOF)
[4] 一文读懂异常检测 LOF 算法(Python代码)- 东哥起飞,知乎:***/p/448276009
LOF是基于密度的经典算法(Breuning et. al. 2000),通过给每个数据点都分配一个依赖于邻域密度的离群因子 LOF,进而判断该数据点是否为离群点 。它的好处在于可以量化每个数据点的异常程度(outlierness) 。
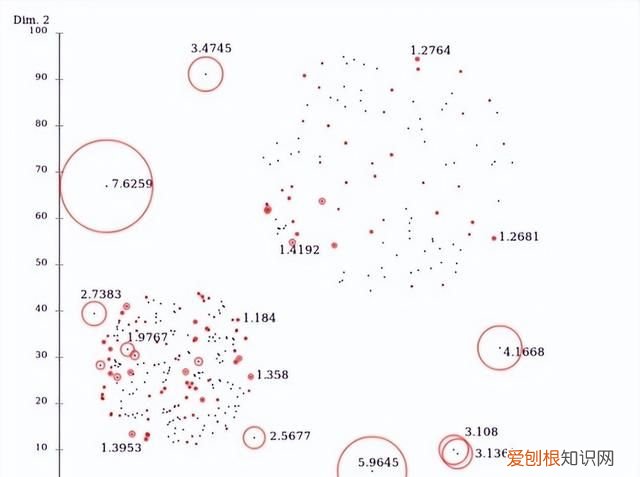
文章插图
图3:LOF异常检测
数据点P的局部相对密度(局部异常因子)=点P邻域内点的平均局部可达密度跟数据点P的局部可达密度的比值:
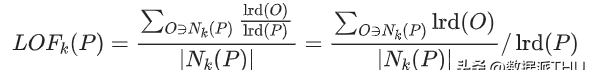
文章插图
数据点P的局部可达密度=P最近邻的平均可达距离的倒数 。距离越大,密度越小 。
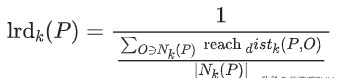
文章插图
点P到点O的第k可达距离=max(点O的k近邻距离,点P到点O的距离) 。
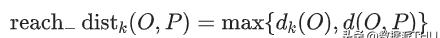
文章插图

文章插图
图4:可达距离
点O的k近邻距离=第 k个最近的点跟点O之间的距离 。
整体来说,LOF算法流程如下:
● 对于每个数据点,计算它与其他所有点的距离,并按从近到远排序;
● 对于每个数据点,找到它的K-Nearest-Neighbor,计算LOF得分 。
from sklearn.neighbors import LocalOutlierFactor as LOFX = [[-1.1], [0.2], [100.1], [0.3]]clf = LOF(n_neighbors=2)res = clf.fit_predict(X)print(res)print(clf.negative_outlier_factor_)2. Connectivity-Based Outlier Factor (COF)
[5] Nowak-Brzezińska, A., & Horyń, C. (2020). Outliers in rules-the comparision of LOF, COF and KMEANS algorithms. *Procedia Computer Science*, *176*, 1420-1429.
[6] 機器學習_學習筆記系列(98):基於連接異常因子分析(Connectivity-Based Outlier Factor) - 劉智皓 (Chih-Hao Liu)
COF是LOF的变种,相比于LOF,COF可以处理低密度下的异常值,COF的局部密度是基于平均链式距离计算得到 。在一开始的时候我们一样会先计算出每个点的k-nearest neighbor 。而接下来我们会计算每个点的Set based nearest Path,如下图:
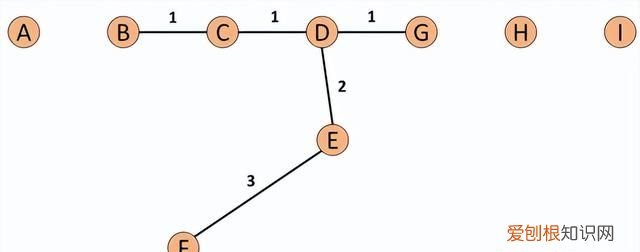
文章插图
图5:Set based nearest Path
假使我们今天我们的k=5,所以F的neighbor为B、C、D、E、G 。而对于F离他最近的点为E,所以SBN Path的第一个元素是F、第二个是E 。离E最近的点为D所以第三个元素为D,接下来离D最近的点为C和G,所以第四和五个元素为C和G,最后离C最近的点为B,第六个元素为B 。所以整个流程下来,F的SBN Path为{F, E, D, C, G, C, B} 。而对于SBN Path所对应的距离e={e1, e2, e3,…,ek},依照上面的例子e={3,2,1,1,1} 。
所以我们可以说假使我们想计算p点的SBN Path,我们只要直接计算p点和其neighbor所有点所构成的graph的minimum spanning tree,之后我们再以p点为起点执行shortest path算法,就可以得到我们的SBN Path 。
而接下来我们有了SBN Path我们就会接着计算,p点的链式距离:
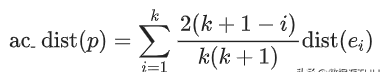
文章插图
有了ac_distance后,我们就可以计算COF:
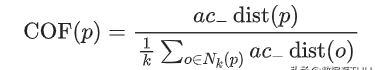
文章插图
# ***/p/362358580from pyod.models.cof import COFcof = COF(cOntamination= 0.06, ## 异常值所占的比例 n_neighbors = 20, ## 近邻数量 )cof_label = cof.fit_predict(iris.values) # 鸢尾花数据print("检测出的异常值数量为:",np.sum(cof_label == 1))
推荐阅读
-

-
-
-
-

-
-
-
-
-
- 考研性价比高的专业,适合考研的专业有哪些
- 要如何看电脑型号,怎么才能知道自己电脑的型号?
- vcf文件要怎么转换成excel
- 韩国人为什么喜欢上吊 为什么自杀的人喜欢上吊
- 安卓手机怎么截图,安卓手机如何截屏
- 为什么自杀的人不顾亲人的感受
- 公主为什么自称哀家 为什么自称哀家
- 坎普为什么被称为雨人 为什么周伟被称为中国雨人
- 周鹏为什么能当队长 为什么周鹏是队长