2. AutoEncoder
[13] 利用Autoencoder进行无监督异常检测(Python) - SofaSofa.io,知乎:***/p/46188296
[14] 自编码器AutoEncoder解决异常检测问题(手把手写代码) - 数据如琥珀,知乎:***/p/260882741
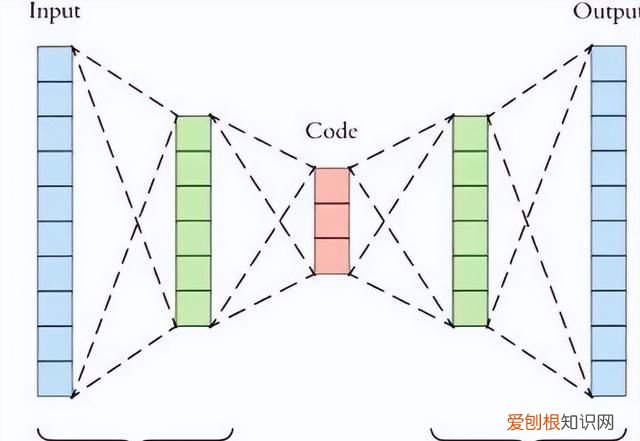
PCA是线性降维,AutoEncoder是非线性降维 。根据正常数据训练出来的AutoEncoder,能够将正常样本重建还原,但是却无法将异于正常分布的数据点较好地还原,导致还原误差较大 。因此如果一个新样本被编码,解码之后,它的误差超出正常数据编码和解码后的误差范围,则视作为异常数据 。需要注意的是,AutoEncoder训练使用的数据是正常数据(即无异常值),这样才能得到重构后误差分布范围是多少以内是合理正常的 。所以AutoEncoder在这里做异常检测时,算是一种有监督学习的方法 。
文章插图
图11:自编码器
# Ref: [***/p/260882741](***/p/260882741)import tensorflow as tffrom keras.models import Sequentialfrom keras.layers import Dense# 标准化数据scaler = preprocessing.MinMaxScaler()X_train = pd.DataFrame(scaler.fit_transform(dataset_train), columns=dataset_train.columns, index=dataset_train.index)# Random shuffle training dataX_train.sample(frac=1)X_test = pd.DataFrame(scaler.transform(dataset_test), columns=dataset_test.columns, index=dataset_test.index)tf.random.set_seed(10)act_func = 'relu'# Input layer:model=Sequential()# First hidden layer, connected to input vector X.model.add(Dense(10,activation=act_func, kernel_initializer='glorot_uniform', kernel_regularizer=regularizers.l2(0.0), input_shape=(X_train.shape[1],) ) )model.add(Dense(2,activation=act_func, kernel_initializer='glorot_uniform'))model.add(Dense(10,activation=act_func, kernel_initializer='glorot_uniform'))model.add(Dense(X_train.shape[1], kernel_initializer='glorot_uniform'))model.compile(loss='mse',optimizer='adam')print(model.summary())# Train model for 100 epochs, batch size of 10:NUM_EPOCHS=100BATCH_SIZE=10history=model.fit(np.array(X_train),np.array(X_train), batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, validation_split=0.05, verbose = 1)plt.plot(history.history['loss'], 'b', label='Training loss')plt.plot(history.history['val_loss'], 'r', label='Validation loss')plt.legend(loc='upper right')plt.xlabel('Epochs')plt.ylabel('Loss, [mse]')plt.ylim([0,.1])plt.show()# 查看训练集还原的误差分布如何,以便制定正常的误差分布范围X_pred = model.predict(np.array(X_train))X_pred = pd.DataFrame(X_pred, columns=X_train.columns)X_pred.index = X_train.indexscored = pd.DataFrame(index=X_train.index)scored['Loss_mae'] = np.mean(np.abs(X_pred-X_train), axis = 1)plt.figure()sns.distplot(scored['Loss_mae'], bins = 10, kde= True, color = 'blue')plt.xlim([0.0,.5])# 误差阈值比对,找出异常值X_pred = model.predict(np.array(X_test))X_pred = pd.DataFrame(X_pred, columns=X_test.columns)X_pred.index = X_test.indexthreshod = 0.3scored = pd.DataFrame(index=X_test.index)scored['Loss_mae'] = np.mean(np.abs(X_pred-X_test), axis = 1)scored['Threshold'] = threshodscored['Anomaly'] = scored['Loss_mae'] > scored['Threshold']scored.head()七、基于分类的方法
1. One-Class SVM
[15] Python机器学习笔记:One Class SVM - zoukankan,博文:***/wj-1314-p-10701708.html
[16] 单类SVM: SVDD - 张义策,知乎:***/p/65617987
One-Class SVM,这个算法的思路非常简单,就是寻找一个超平面将样本中的正例圈出来,预测就是用这个超平面做决策,在圈内的样本就认为是正样本,在圈外的样本是负样本,用在异常检测中,负样本可看作异常样本 。它属于无监督学习,所以不需要标签 。
推荐阅读


- 考研性价比高的专业,适合考研的专业有哪些
- 要如何看电脑型号,怎么才能知道自己电脑的型号?
- vcf文件要怎么转换成excel
- 韩国人为什么喜欢上吊 为什么自杀的人喜欢上吊
- 安卓手机怎么截图,安卓手机如何截屏
- 为什么自杀的人不顾亲人的感受
- 公主为什么自称哀家 为什么自称哀家
- 坎普为什么被称为雨人 为什么周伟被称为中国雨人
- 周鹏为什么能当队长 为什么周鹏是队长